

Duchenne Parent Project in the Netherlands announced that their patient-led online registry (The Duchenne Data Platform) has successfully deployed an innovative and sustainable FAIR solution, achieving a FAIR status.
We are delighted to hear our partners in the Netherlands have achieved the first ever FAIR status for their data platform. Furthermore, Action Duchenne are currently deploying this platform, and it is our intention to achieve FAIR status with our UK DMD Registry. We wish to thank Duchenne Parent Project for their ground-breaking work, which will ultimately benefit the Duchenne families living here in the UK.
Florence Boulton – National Director, Action Duchenne
What is FAIR status?
The adoption of FAIR data practices to make data Findable, Accessible, Interoperable and Reusable for humans and machines optimises the (re)use of Duchenne muscular dystrophy consented-data collected and safeguarded by the platform.
- Findability – machines can find DDP
- Accessibility – machines can read that access is open for metadata
- Interoperability – a FAIR transformation solution has been implemented (called CDE-in-a-Box) making DDP ready to be linked to other registries
- Reusability – once the FAIR transformation workflow is on, machines will know which licenses they have for reuse of our data.
Making data readable by both humans and machines (ie, machines knowing what our data mean) can be achieved by special software and “knowledge representation” technology. This enables efficient and real-time analysis across multiple data sources without moving data. It also allows us to specify and control (1) what type of data queries can be made within a given source of data and by whom, and (2) what data (e.g., the results of queries) can be seen outside of the source.
Specifically, FAIR algorithms may have permission to calculate summary data from all pseudonymized data inside a data source, but only deidentified and aggregated summary data are allowed to leave the source for human inspection. Applying knowledge representation technology during a FAIRification process makes conditions for access transparent and assessable and facilitates compliance with the General Data Protection Regulation. Consequently, FAIR data can be used appropriately by researchers, health care providers, regulators, family members, and patients to accelerate discoveries for early diagnosis and innovative treatments. Furthermore, FAIR data enables treatments to be personalized to the needs of individual patients. This is ultimately what patients with DMD/BMD want.
Innovative FAIR Solution
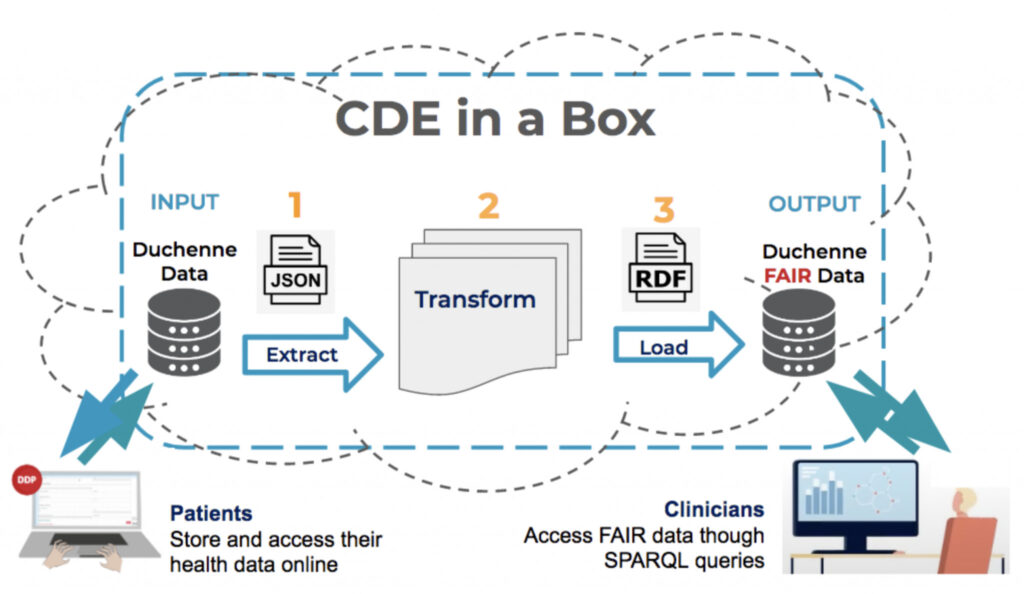
To achieve this goal, an innovative and sustainable FAIR solution called ‘CDE-in-a-Box’ (Figure1.) has been developed and deployed for the Duchenne Data Platform. The ‘CDE-in-a-Box’ also known as ‘FAIR-in-a-Box’ describes an automated FAIR transformation workflow. The ‘CDE’ part refers to the set of 16 Common Data Elements (CDEs) recommended by the European Platform on Rare Disease Registration (EU RD Platform) that should be implemented by all RD registries (e.g. Genetic diagnosis). The set of Common Data Elements is a core component of a FAIRification process. The term ‘Box’ gives the impression that everything happens automatically in a single place. In reality, cloud-based servers are communicating with each other through API calls.
Sustainable FAIR Approach
The CDE-in-a-Box follows a sustainable approach as it is based on international standards, recommended at European level by EJP-RD. The same standards were deployed by other registries that have implemented a FAIRification process such as the VASCA Registry for Vascular Anomalies [3].
Initially, the FAIR Transformation solution was commissioned by the Duchenne Parent Project in the Netherlands. The fact that their registry (DDP) was built with interoperability in mind, presented an ideal use-case. Once the FAIR solution was found and deployed in collaboration with FAIR experts within EJP-RD, the Duchenne Parent Project opted towards making their code of CDE-in-a-Box an open source. Their generosity stems from their belief in FAIR as a new paradigm for optimising data ‘visiting’ and as a result, pledged to support others in their own FAIR endeavours [4]. ERN Euro-NMD core registry as well as DM-Scope, a national French registry for Myotonic Dystrophies are both implementing this FAIR solution and their tests are showing promising results.
Contact
For any additional information, please reach out to Nawel van Lin, Project Manager FAIR Duchenne Data.
Additional Technical Information:
How does ‘CDE-in-a-Box’ work in practice?
First of all, it makes the implementation of a FAIR transformation pipeline more reachable to those without Linked Data or FAIR expertise. It’s an innovative solution because all the complicated programming has already been done and the actual FAIR transformation happens in three steps:
- Extract: The original data is uploaded into a simple CSV file and extracted through an API call.
- Transform: The CSV file containing the ontologised data is sent to receive a series of transformations, automatically.
- Load: The output is FAIR data in RDF format (Resources Description Framework and the machine-language format necessary for SPARQL queries) which is then loaded into a Triplestore.
FAIR data are then ready to be linked and merged if they’re related to the same topic or disease. The nightly updates make it possible for any old data to be deleted and the refreshed data to be updated without human intervention.
What was involved in the technical development?
Through a team-based iterative [1] approach within the European Joint Programme on Rare Diseases (EJP-RD), experts created semantically grounded data models to represent each of the CDEs, using the SemanticScience Integrated Ontology (SIO) as the core framework for representing the entities and their relationships. Within that framework, they mapped the concepts represented in the CDEs, and their possible values, into domain ontologies such as the Human Phenotype Ontology. Then, they deployed an ETL pipeline (Extract-Transform-Load) via docker-compose, where every component is packaged as a docker image and uses a docker network to facilitate communication between the components. Finally, they created a suite of four docker images that are referred-to as the “CDE-in-a-Box”. The instructions for running this process, as well as how to interact with CDE-in-a-Box, are available on a dedicated GitHub [2].
 Happy Holidays from our National Director
Happy Holidays from our National Director
